
This is a fun project my friend Lukas and I worked on for a course on natural language processing (NLP). We used the One Million Posts Corpus which contains user comments posted to the Austrian newspaper DerStandard. The goal was to perform author attribution, so to determine the author of a forum post.
To do so, we mainly looked at the writing style of the post, as this was mainly an exercise in the field of NLP. We call the attributes that give away a user based on their writing style stylometric. There has been a lot of research in this field and for our analysis, we mainly looked at rather classical features such as alpha-char-ratio, punctuation, lengths, etc.
However, to make it more interesting, we also looked at how these features compared to taking into account other metadata and the actual post’s content for the predictions. In the end we looked at the following:
- stylometric attributes
- content (by means of word embeddings)
- metadata
- date statistics (time of day, day of the week)
- rating of the post and whether it was a response to another user’s post
- article categories (what was the category of the article to which this comment was posted)
- article named entities (what are the named entities appearing in the article to which this comment was posted)
Our model was a deep neural network with recurrent layers (primarily GRUs) for the content embeddings and a separate dense structure for the other input features:
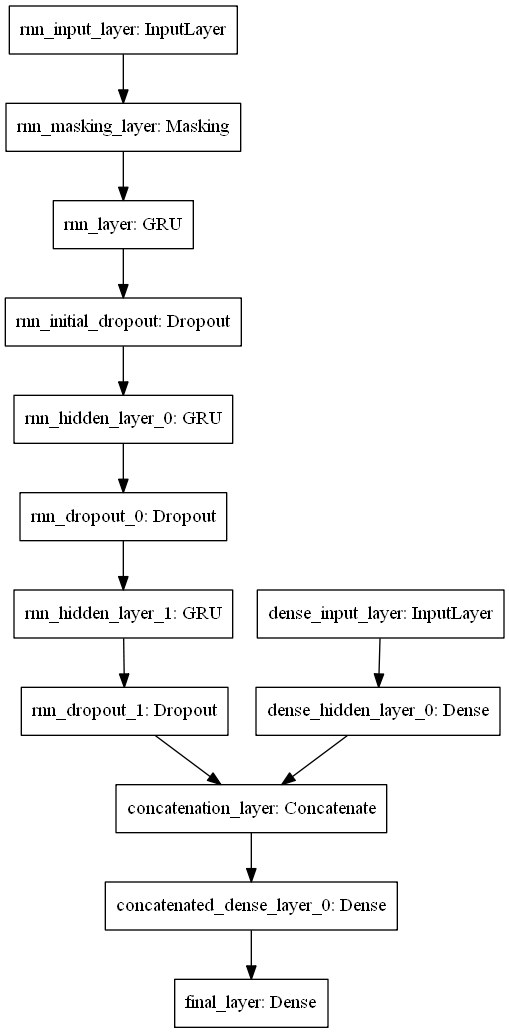
Obviously we did some model selection to find the ideal number of layers and the configuration of hyper-parameters.
Key findings
The main things we found were the following:
- We were best able to predict the post authors when using the stylometric features and the named entities of the articles itself. The latter allows for the assumption that people tend to comment on articles in the same genre.
- The statistics on post dates weren’t as helpful as we had thought. Users don’t seem to have a clear enough posting routine to make accurate predictions based on the day or time they are posting.
- Even the very simple stylometric features we used already yielded quite good prediction results. In future work, it might make sense to look at this in detail and try to find out how to squeeze most out of the writing style alone.
Overall, it was a very fun project with much room for further analysis. In case you want to check out all of what we did, you can find the full report on GitHub.